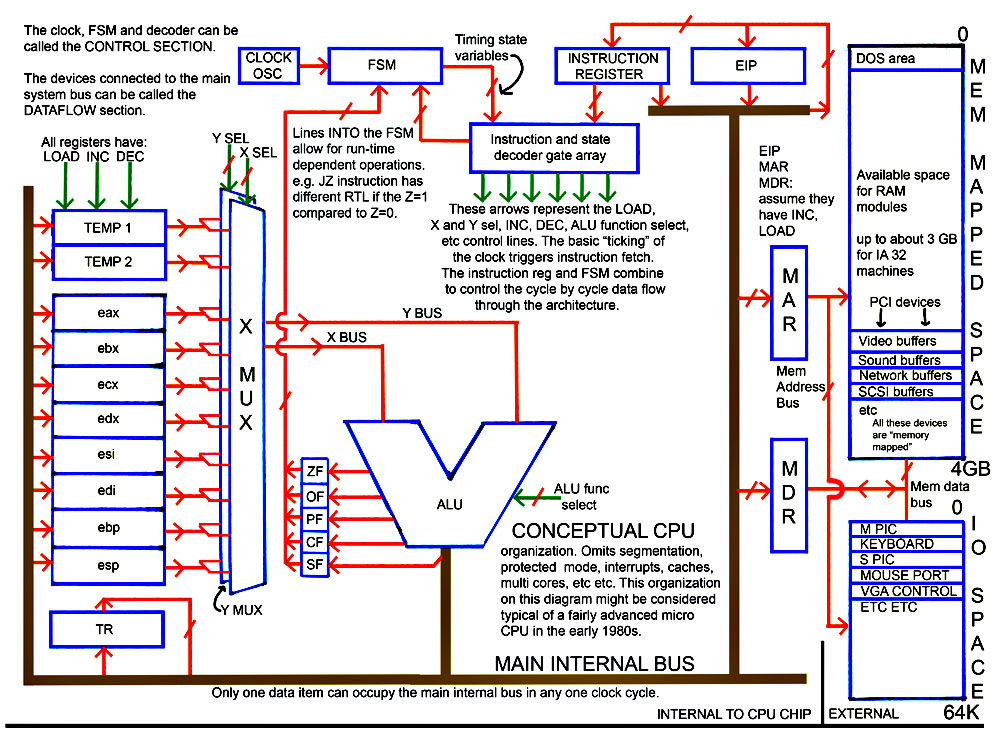
The following diagram shows a simple hypothetical x86 dataflow architecture.
For exam purposes, you are expected to be able to trace the data flow transfers for the following situations:
instruction fetch
Register to register operation, e.g. ADD eax,abx
Register immediate, e.g. ADD, eax, constant
Register to memory or memory to register, e.g ADD eax,[esi] or MOV [edi],ebx
Register to memory with offset, e.g. AND eax,[esi+constant]
push and pop
call and ret
jump
You can download a better quality diagram and print it out from any image printing program if you use this link..
Since we have so little time, this portion of the course will be merely a brief hand-waving summary of several of the newer developments. You should be able to state what the item means, and how it helps improve computational throughput, and give any significant issues discussed in the class lectures.
1. Caches. Unified vs separate data/instruction caches, i.e. Von Neumann and Harvard architectures.
2. Pipelining and instruction prefetch.
3. Superscalar operation
4. Branch prediction and speculative execution.
5. Simultaneous multithreading.
6. Multiple cores